回复
-
- 查看全部{{ item.replyCount }}条回复> 查看更多回复>
- 查看更多回复>
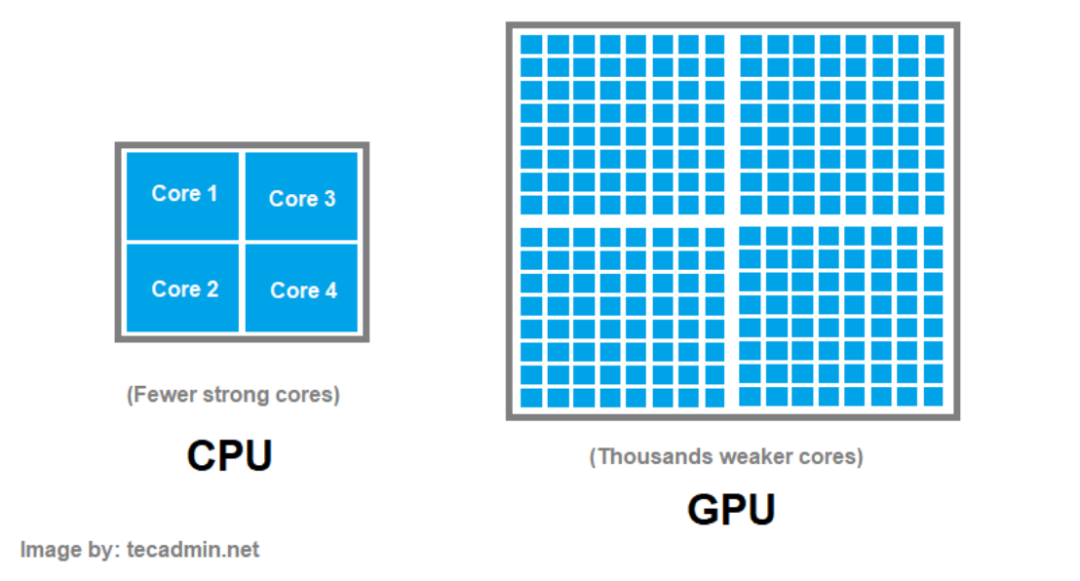
算力赛道要换主角,CPU重登舞台中心。
过去数年,在AI大模型预训练的浪潮下,GPU凭借并行计算能力的绝对优势,成为算力竞争的核心壁垒,也因此成为科技巨头与资本市场共同追逐的焦点。
彼时,NVIDIA H100芯片一卡难求,硅谷巨头们为抢夺GPU资源,甚至将芯片库存量列为财报会议上的核心竞争力指标。这段狂热的历史,在投资者与大众心中刻下了一个根深蒂固的认知:AI = GPU。
但时间来到2026年,当你走进最先进的AI数据中心会发现,困扰行业的算力瓶颈早已不止GPU——内存告急、光模块短缺、电力供应紧张、散热难题凸显,算力缺口正从单点扩散到整个基础设施链条。
在这些被热议的赛道之外,不禁想追问:还有哪些被忽视的机会?答案,藏在那个曾被视作“无聊配角”的硬件里:CPU(中央处理器)。
若你觉得“CPU缺货”的说法有违直觉,不妨看看近期产业巨头的真实动向:
AMD CEO苏姿丰(Lisa Su)在财报会议上直言,EPYC服务器CPU需求“远超预期”。在核心的数据中心领域,AMD高端CPU已陷入严重供不应求的境地,交货周期拉长至6个月以上,甚至手握10%-15%的涨价话语权。
一度陷入低谷的Intel,在2025年底意外迎来服务器CPU库存见底。公司不得不紧急调整产能,将原本预留给PC产线的晶圆,转投服务器CPU生产以缓解缺口。
最具说服力的信号,来自“GPU霸主” NVIDIA——其AI基础设施主管公开承认:“在扩展AI与智能体(Agentic)工作流时,CPU正成为我们的瓶颈。”
在这份深度报告中,将拆解CPU重回算力舞台中央的完整逻辑:
CPU vs GPU—— 必须搞懂的底层逻辑
在探讨2026年超大规模数据中心为何大举采购CPU之前,需要先打破一个过时的迷思:“AI = GPU,GPU越强AI越聪明”。要理解这一认知的转变,不妨回溯算力产业的三段历史:为什么过去40年是CPU称霸?为什么过去10年GPU逆袭上位?而现在,算力天平为何再次向CPU倾斜?
40年CPU霸权,源于“通用性”基因
在个人电脑与早期服务器时代,CPU(中央处理器)是整台设备的绝对核心。无论是Intel还是AMD,其CPU设计的底层哲学只有一个:通用性(General-Purpose)。
电脑需要处理的任务繁杂且多变:开机时加载操作系统、移动鼠标光标、一边播放Spotify音乐,一边打开数十个Chrome浏览器标签页,同时后台还在下载文件。这些任务的共同特点是:充满不确定性与复杂逻辑判断。
“如果用户点击这个按钮,就打开新窗口”“如果网络突然中断,就弹出错误提示”——CPU正是为这种“如果A发生,就执行B”的分支逻辑而生。它就像一把瑞士军刀,功能全面且切换任务的速度极快。在那个算力瓶颈聚焦于“逻辑处理效率”的年代,CPU的运算速度直接决定了设备的流畅度。
GPU称霸AI时代,赢在“并行计算”优势
GPU(图形处理器)的诞生初衷与AI毫无关联——它是为“玩游戏”而生的。
在3D游戏中,屏幕上数百万个像素的颜色、光影反射效果,需要每秒钟重新计算60次。这类计算的特点鲜明:运算逻辑简单、数据量庞大、且各像素的计算过程互不干扰。此时,主打通用性的CPU就显得“笨拙”了。就像用一把精密的瑞士军刀去切一万颗卷心菜,远不如一万把菜刀同时开工高效。NVIDIA正是抓住了这一痛点,设计出内置成千上万个“微小、简单且可并行工作”运算核心的GPU。
而GPU与AI的结缘,源于一场“技术巧合”。2012年左右,科学家们发现:深度学习与神经网络的底层数学逻辑,和3D游戏的像素渲染运算,本质上完全一致。训练一个AI大模型(比如让它“读完”一座图书馆的书籍),对计算机而言就是将文字转化为数字,再执行数万亿次的“矩阵乘法”。这是一种标准化、规模化的算术运算。
CPU处理这类海量简单任务时,会因核心数量不足陷入“算力拥堵”;而GPU的数千个并行核心可同时启动,运算速度是CPU的几十倍甚至上百倍。这正是2024年以前“大模型预训练时代”,GPU独霸算力市场的核心原因——彼时的AI就像一个“死记硬背的学生”,其核心需求就是纯粹的并行数学运算。
一万名士兵(GPU)vs十位大学教授(CPU)
GPU:一万名整齐划一的士兵。这支军队最擅长“标准化并行算术”。若让所有人同时计算“1+1=2”,他们能瞬间完成任务。但他们的短板也很明显——应变能力极差。一旦遇到逻辑分支变化或复杂任务,整支队伍就会陷入混乱,需要重新整队才能继续。更重要的是,士兵们不具备独立运行操作系统和复杂软件的能力。
CPU:十位顶尖的大学教授。教授的数量虽少,却拥有极强的“复杂决策与逻辑判断能力”。他们专精于处理“如果……就……”的条件分支,能瞬间切换策略,从容应对不可预测的任务。更关键的是,教授们天生就是为操控各类软件、网络与数据库而生的——他们是整个算力系统的“指挥官”。
2026年,算力天平向CPU倾斜的底层逻辑
总结来说,过去十年的AI突破,建立在“将所有问题转化为并行数学运算”的基础上,这造就了GPU的黄金时代。彼时的AI,就像一个坐在图书馆里死记硬背的学生,只需要无穷无尽的GPU “士兵”帮忙翻书、做算术。但到了2026年,科技巨头们发现了一个新命题:AI已经“背完了书”,背完了书”,现在需要走进现实世界“解决问题”。
当AI的行为模式从“静态的文本生成”转向“动态的逻辑推理与工具操作”,仅靠一万名只会做算术的士兵已经远远不够。算力系统突然需要大量的CPU “教授”——指挥GPU军队、操控各类软件、为AI搭建复杂的虚拟训练环境。GPU是AI的“肌肉”,CPU则是“神经系统”。当肌肉已经足够强壮时,整个AI产业的发展速度,开始由能指挥肌肉的“神经系统”决定。
2026 年,三股力量同时引爆 CPU 需求
2023-2024年,全球科技巨头疯抢GPU;2025年,行业焦点转向内存(HBM)。而到了2026年,数据中心的最新算力瓶颈,悄然落在了曾经的“配角” CPU身上。这一转变的背后,是AI产业演进跨过的关键分水岭——三股趋势的交汇共振,其中前两股发生在GPU机架“内部”,第三股则在机架“外部”开辟了全新战场。
推论时代来临——AI使用量的指数级爆炸
这是最容易被大众忽视,却体量最为庞大的一股力量。
在2026年3月的GTC大会上,NVIDIA CEO黄仁勋(Jensen Huang)正式宣告“推论时代”(Age of Inference)全面降临。这意味着,AI算力的最大消耗端,已经从实验室里的“模型训练”,转向现实世界中的“用户服务”。
背后的逻辑很简单:训练一个顶级大模型,可能需要数万张GPU连续运算数月,这是一项“一次性工作”;但模型上线后,全球数亿用户每天用它搜索信息、编写代码、进行医疗诊断与金融分析——这种“推论”需求是持续不断、永无止境的。
但推论不等于“只用GPU”。
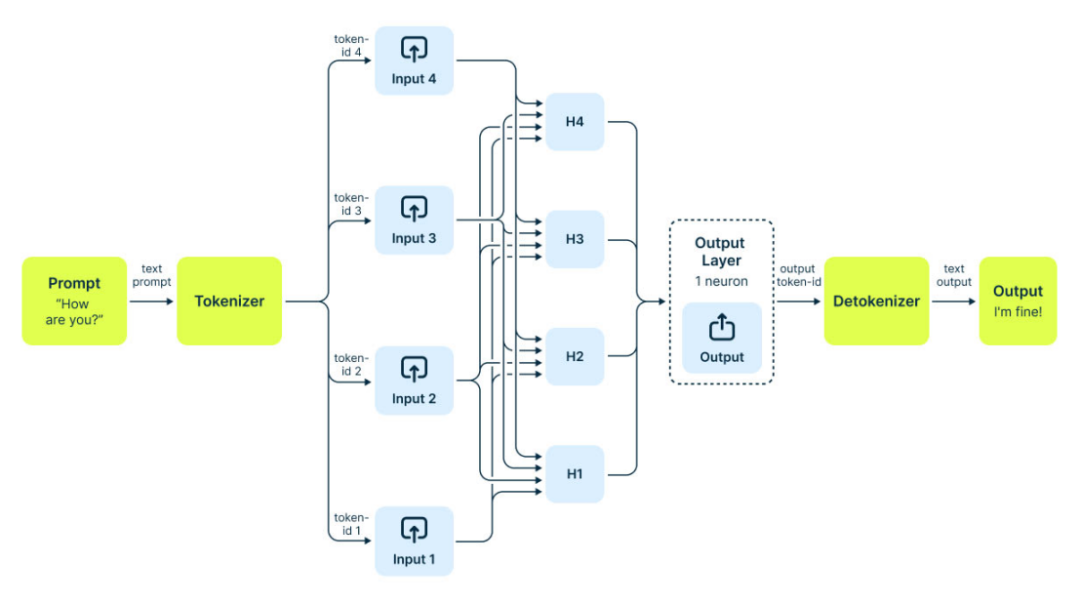
每一次用户发起请求,CPU都需要承担大量繁琐的“前后端工作”:接收请求、任务排队、分批处理、组装提示词(Prompt)、执行Tokenization(将人类语言转化为模型可识别的碎片),最后将GPU的运算结果格式化,反馈给用户。
如果说“模型训练”是花几个月建造一座高科技工厂,那么“推论”就是工厂24小时不间断接收订单。工厂运转时,不能只有负责生产的机器人(GPU),更需要大量调度员、包装员和品管员(CPU)——确保每一张订单精准、准时交付。
当全球AI推论量从“每天几百万次”飙升至2026年的“每天几十亿次”,CPU的工作量也随之呈现指数级增长。即便单次请求的CPU工作量不变,仅“订单量”的爆发,就足以让CPU成为新的算力瓶颈。
这也正是AMD CEO苏姿丰在2026年初强调的:“我们看到CPU需求显著上升,这是推论需求大幅增长的直接结果。”据多家机构预测,2026年推论算力占AI总算力的比例将超过60%-70%,且仍在加速攀升。
Agentic AI——单次请求的CPU工作量暴增5-10倍
如果说推论时代带来的是“量”的爆炸,那么Agentic AI(智能体AI) 就是“质”的颠覆——它让单次请求的CPU工作量直接提升5-10倍。在ChatGPT时代,用户提出一个问题,GPU运算一次就能给出答案。这是一条单向直线,CPU仅需承担少量辅助工作。
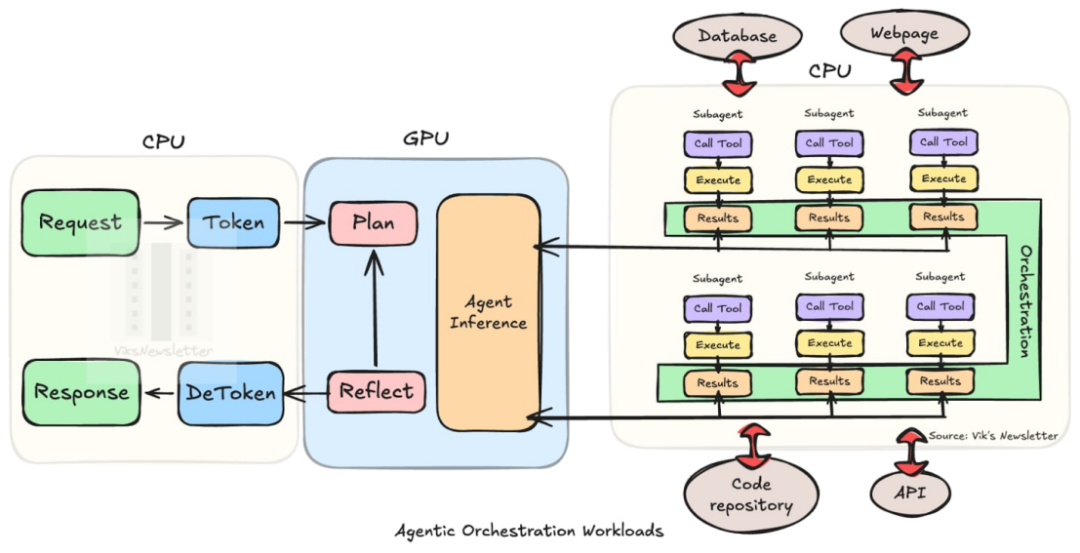
但2026年的Agentic AI完全不同。当你对AI说“帮我规划下周东京行程并预订机票”,AI不会直接输出一段文字,而是启动一个多步骤的“循环流程”:规划行程(CPU)→打开旅游网站比价(CPU调用工具)→遇到网站报错,重新尝试(CPU逻辑判断)→优化行程方案(GPU推理)→填写机票订单并验证(CPU)
在这个复杂循环中,GPU仅负责“思考”的短短几毫秒,而50%-90%的延迟与工作量,都压在了CPU身上。CPU需要承担调用API、查阅数据库、执行代码、管理记忆状态等核心任务。
再用一个比喻理解这一变化:过去,8台机器人(GPU)只需要1个领班(CPU)——机器人接到指令就能独立完成工作;现在,每台机器人做完一步,都要回头询问领班:“下一步怎么做?”“网页报错了怎么办?”“帮我联系航空公司确认座位!”——结果就是领班忙到崩溃,而昂贵的机器人只能在一旁“发呆”等待指令。
为了减少GPU闲置,数据中心不得不持续增加CPU数量,这直接改变了GPU机架内的CPU:GPU配比——过去是1:8,现在飙升至1:2甚至1:1。以NVIDIA最新的Vera Rubin NVL72机架为例,其内置72颗GPU的同时,配备了高达36颗CPU。
这里需要明确一个关键区别:推论时代让“请求数量变多”,Agentic AI让“单次请求的CPU工作量变大”。两者形成“乘法效应”,这正是CPU需求爆发远超华尔街分析师去年预测的核心原因。
RL训练与合成数据——AI的“练习场”,完全跑在CPU上
前两股力量聚焦于GPU机架“内部”的推论端,而第三股力量则在机架“外部”——由纯CPU组成的服务器农场,开辟了全新的算力战场。
2025年底,科技巨头们遇到了一个新瓶颈:互联网上的人类高质量文本数据,几乎已被AI “读完”。想要实现Agentic模型的能力突破,AI不能再依赖“死记硬背”,必须学会“自己跟自己练习”——这就是强化学习(RL, Reinforcement Learning)与合成数据技术崛起的背景。
过去的大模型预训练,就像让AI “读完一整座图书馆”。对计算机而言,这个过程的本质是文字转数字,再执行超大规模的加减乘除——这类纯数学任务,是GPU的绝对主场。而现在的强化学习,更像教一个学徒修车或订机票:AI需要亲自“动手操作”——点击按钮→验证结果→修正错误→再次尝试。
当AI练习“预订机票”时,我们需要为它搭建一个虚拟的航空公司网站(环境模拟器)。这个网站有菜单、按钮、报错提示,是一个标准的“通用软件”。整个练习过程,充满了“如果……就……”的逻辑分支:如果AI点错按钮,网站要弹出警告;如果网络中断,要显示错误代码。面对这种复杂的逻辑判断,只会做算术的GPU运转起来慢如乌龟,而擅长“运行通用软件”的CPU则如鱼得水。
为了让AI快速迭代升级,前沿实验室不会只搭建一个模拟网站,而是同时开启1万- 10万个平行的虚拟环境。这10万个虚拟世界,需要海量CPU核心充当“考场管理员”与“裁判”——监控AI的练习过程、评估任务完成度、生成“成绩单”,再将数据反馈给GPU,让GPU更新模型参数。
我们可以用“运动员与练习场”的关系,理解当下的算力分工:GPU是运动员的“肌肉”,负责最终的思考与发力;CPU是“练习场与教练”,负责搭建训练环境并提供反馈。
过去,运动员只需要看比赛录像学习(GPU读取数据),CPU需求极低;现在,运动员需要下场训练数百万次——没有足够的CPU搭建练习场,运动员的能力就会停滞不前。这正是2026年OpenAI、xAI、Anthropic与Meta等前沿实验室,大举采购纯CPU服务器搭建RL模拟农场的原因。SemiAnalysis在2026年2月的报告中直言:“前沿AI实验室的CPU,已经不足以支撑RL训练需求。”而NVIDIA推出的Vera CPU机架(单机架搭载256颗CPU),正是为了同时运行超过22500个并行RL环境而生。
推论需求的指数级增长、Agentic AI带来的单次请求工作量飙升、强化学习所需的海量虚拟练习场——这三股力量在2026年完美交汇,将CPU从幕后推向了算力舞台的中央。
既然CPU已成算力刚需,那么市场上的主流玩家们,又是如何布局应战的?为什么GPU霸主NVIDIA要跨界做CPU?
CPU 架构战争——AMD EPYC vs Intel Xeon vs NVIDIA Grace/Vera
当Agentic AI与强化学习将CPU重新推上核心舞台,你可能会问:“随便买哪一家的CPU,不都一样吗?”答案是:完全不一样。现代数据中心的CPU,早已不是“主频越高,性能越强”的单一维度比拼。AMD EPYC、Intel Xeon与NVIDIA Grace/Vera三大产品线,在指令集、物理架构、GPU协同方式上,存在着根本性的设计哲学分歧。
要理解当下的CPU战争,首先要回顾算力产业最古老的阵营之争——x86与ARM两大指令集架构的对决。

过去几十年,无论是台式机、笔记本还是服务器,搭载的几乎都是x86架构CPU(采用复杂指令集CISC)。可以把它看作一把功能强大、兼容万物的超级瑞士刀。x86的核心优势,在于无可匹敌的软件兼容性。过去数十年间,全球企业开发的操作系统、数据库、监控工具,几乎都是基于x86架构编写的——直接部署即可运行,无需任何修改。但这份兼容性的代价,是背负了沉重的历史包袱:x86架构内部设计复杂,功耗相对较高。
ARM架构(采用精简指令集RISC)的发展路径,与x86截然不同。它最初是为手机、平板等移动设备设计的,底层哲学是极致省电与高能效比。很长一段时间里,科技圈对ARM的认知都是“省电但性能弱”,认为它只能用于移动设备,登不上服务器的“大雅之堂”。直到几年前,苹果将Mac电脑的Intel x86芯片,替换为自研的ARM架构M系列芯片——这场“苹果革命”彻底颠覆了市场认知:ARM芯片不仅功耗极低,性能还显著超越传统x86芯片。
苹果的成功,让云端巨头们恍然大悟:ARM架构也能做到高性能。到2026年,ARM已正式杀入数据中心市场。不仅NVIDIA的Grace与Vera CPU采用ARM架构,AWS的Graviton、Google的Axion、微软的Cobalt等云厂商自研CPU,也全部基于ARM架构打造。原因很简单:在动辄消耗几十兆瓦电力的AI数据中心里,ARM的能效优势极具吸引力——在部分AI任务中,NVIDIA Vera的能效比是x86架构的1.5-2倍。
这一趋势对投资市场的影响深远:x86架构40年的绝对垄断被打破。云端巨头为降低能耗与成本,正加速导入ARM架构。这也是专注于“架构授权”的ARM Holdings,能在这波浪潮中收获长期结构性红利的原因;而AMD与Intel,则需要依靠深厚的“软件生态护城河”与高核心数设计,捍卫自己的市场份额。
架构之外,芯片的物理设计方式,决定了CPU能集成多少核心,以及核心之间的协同效率。当前市场上主要有三种设计路线:AMD的Chiplet(芯粒)架构、NVIDIA的Monolithic(单片)架构,以及Intel的混合微调方案。
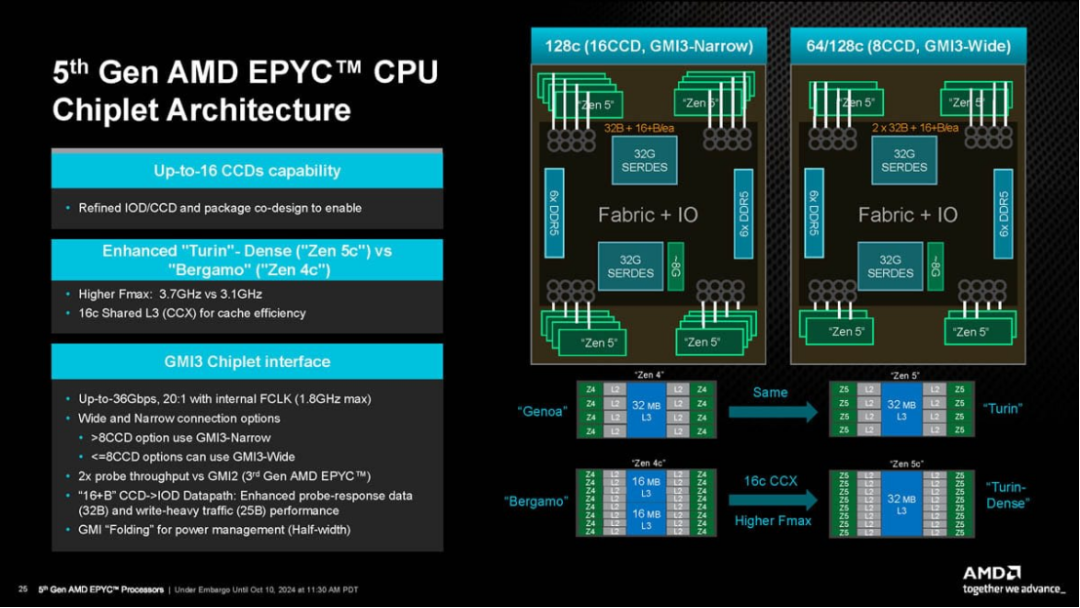
AMD的EPYC系列CPU(如2026年主力型号Turin与Venice),采用的是Chiplet设计。它不追求单块超大芯片,而是将CPU拆解为8-16块“小芯片(CCD)”,再通过中间的I/O芯片,像拼乐高一样组装成完整的处理器。其优点是生产成本低、芯片良率高,且核心数可以无限堆叠。这也是AMD能轻松推出192核甚至256核超高核心数处理器的关键。对于需要同时运行10万个虚拟环境的RL模拟农场而言,这种“人多力量大”的架构堪称完美。其缺点是芯片之间的通信存在微小延迟,在对时延要求极高的场景下,性能会受到一定影响。
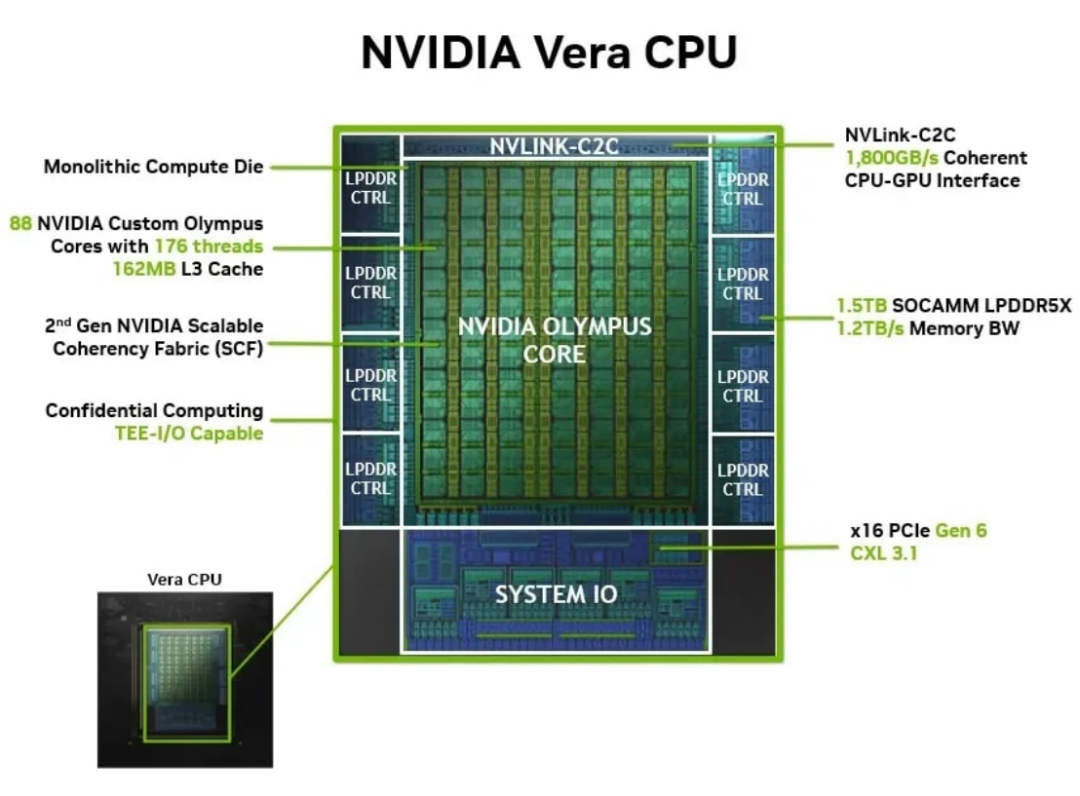
NVIDIA的Vera CPU走了一条完全相反的路线。它是一块巨大的单一芯片,将88个核心全部集成在同一块晶圆上,没有拆分也没有组装。其优点是核心之间的通信几乎没有延迟。在Agentic AI的推论循环中,这种超低延迟的均匀网络,能让CPU与GPU的协同效率达到极致。其缺点是核心数受限于芯片面积,无法像Chiplet架构那样无限扩展(Vera仅88核);且大尺寸芯片的生产难度高、成本昂贵。
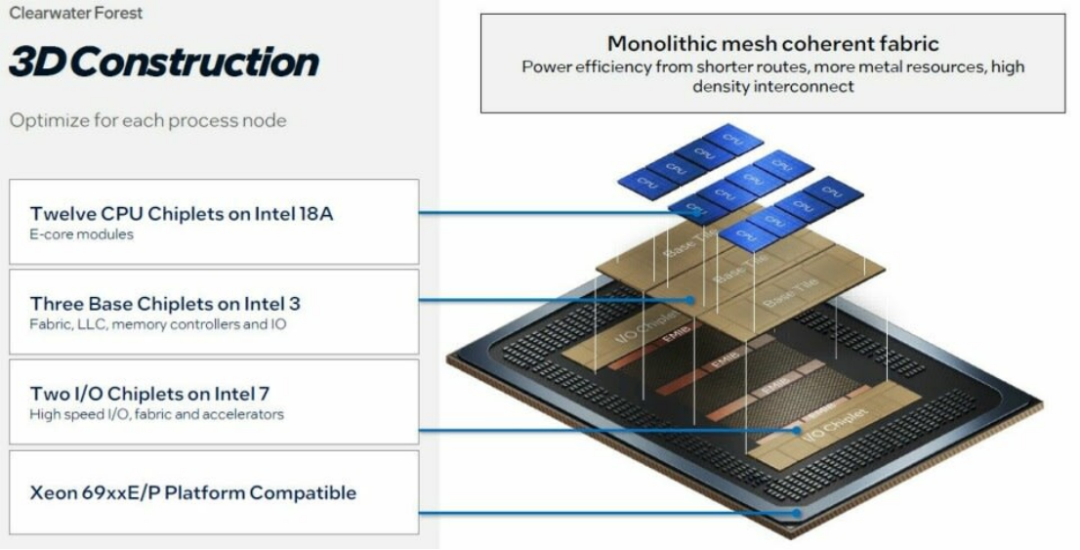
Intel新一代Xeon系列CPU(如Clearwater Forest,搭载288个能效核),则走了中间路线。它同样采用多芯片拼接方案,但使用了先进的EMIB封装技术——通过高密度的互连线路,让拼接后的芯片,在协同效率上无限接近“一整块大石头”。这项技术的研发难度极高,也是Intel实现市场翻盘的关键赌注。
三种架构的差异,直接决定了市场格局的分化:AMD的Chiplet架构,凭借高核心数与低成本优势,成为“纯CPU农场”的绝对霸主;NVIDIA的Monolithic架构,则凭借超低延迟的优势,锁定“GPU机架内部”的核心控制节点。
NVIDIA的独门武器:NVLink-C2C

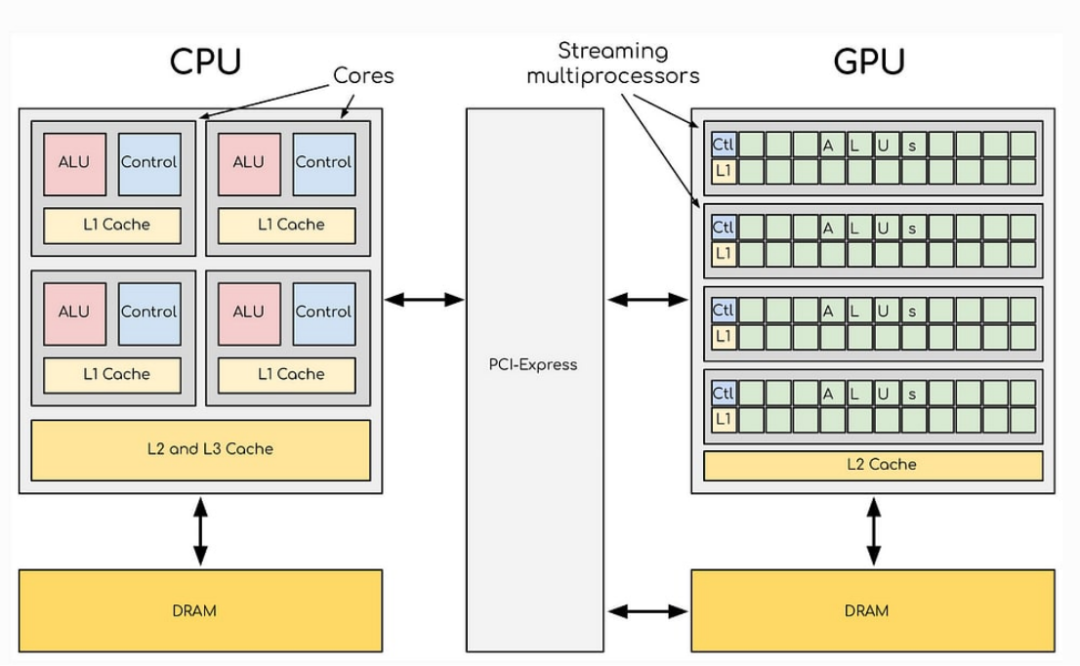
如果仅比拼核心数与能效,NVIDIA很难说服客户放弃AMD与Intel,转而采购自家CPU。NVIDIA真正的技术壁垒,是一项名为NVLink-C2C的硬件互连技术。在传统的AMD或Intel服务器中,CPU与GPU来自不同厂商,两者通过PCIe总线通信。这种连接方式虽然稳定,但带宽有限——当Agentic AI需要CPU与GPU每毫秒都进行高密度数据交换时,PCIe总线就会变成“拥堵的省道”。
NVIDIA的解决方案极具颠覆性:将自家Vera CPU与Rubin GPU,直接集成在同一块基板上(称为Superchip超级芯片),并通过NVLink-C2C搭建一条“私人高铁”。
这条“高铁”的优势体现在两个维度:
1、速度碾压:2026年的Vera/Rubin世代,NVLink-C2C的双向带宽高达1.8TB/s,是传统PCIe总线的7倍以上;
2、内存共享:这是其核心竞争力。通过NVLink-C2C,GPU可以直接访问CPU的内存资源。AI模型的庞大上下文数据(KV Cache),可以直接存储在CPU的低成本大容量内存中,GPU随用随取——完全不需要软件工程师编写复杂的数据搬运程序。
这是NVIDIA最深的硬件护城河。只要客户的AI任务,需要CPU与GPU进行高频次、低延迟的协同(比如前沿的Agentic AI推论),就只能选择NVIDIA的Superchip方案。在这个“紧密耦合”的细分领域,AMD与Intel目前尚无能力提供同级别的硬件支持。

为什么云端巨头不全部换成NVIDIA CPU?
读到这里,可能会产生疑问:“NVIDIA的Vera CPU这么强,为什么云端巨头不全部切换成NVIDIA方案?”
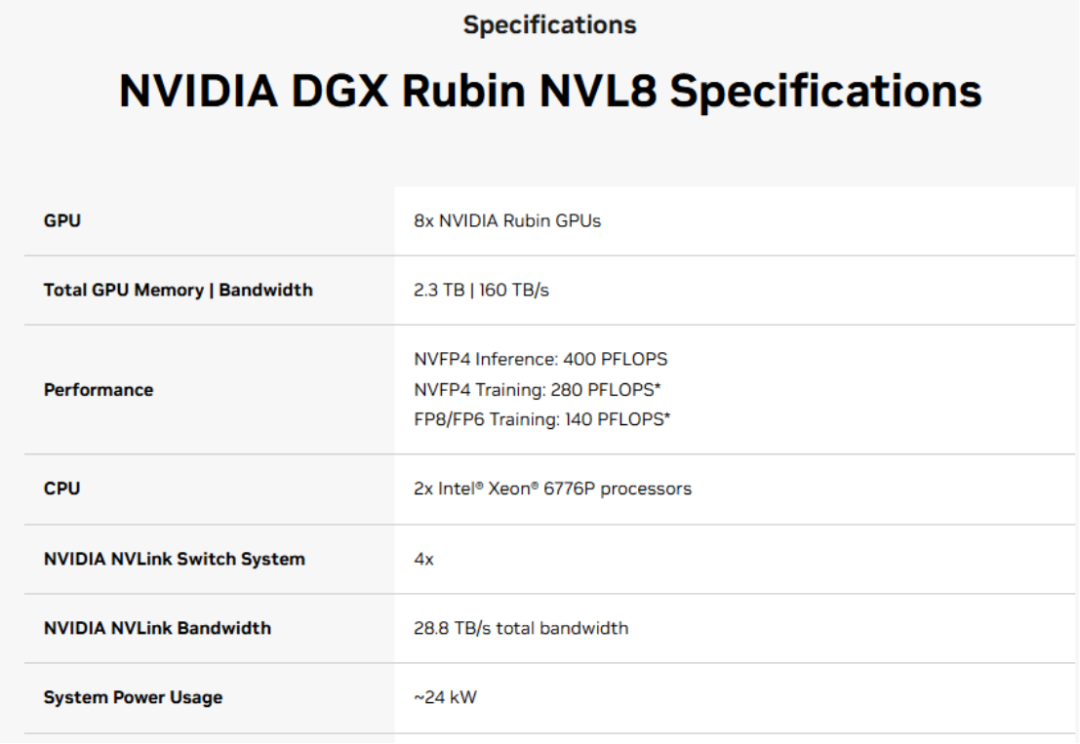
但实际的市场数据给出了相反的答案:2026年,AMD与Intel的服务器CPU持续缺货;甚至连NVIDIA自家的旗舰AI服务器(DGX Rubin NVL8),官方默认搭载的也是Intel Xeon x86 CPU。
背后的原因,主要有四点:
1、核心数无法满足需求:如前文所述,RL模拟农场需要的是“海量并行处理能力”。AMD EPYC单芯片最高可达256核,而NVIDIA Vera仅88核。对于无需与GPU紧密耦合的“纯CPU任务”,AMD的性价比优势显著。
2、软件生态的“路径依赖”:数据中心内部,部署着成千上万的x86架构软件——排程系统、数据库、安全工具等。云端巨头不可能为了一个AI项目,将整个基础设施的底层软件全部重构为ARM版本。
3、产能与供应量限制:NVIDIA的CPU产能,受限于台积电的先进封装工艺,远低于AMD与Intel的规模。云端巨头动辄需要数十万颗CPU,NVIDIA的产能根本无法满足如此庞大的需求。
4、混合部署才是最优解:云端巨头的策略非常清晰——将数据中心划分为两大板块:
核心算力区(GPU训练/推论机架):采用NVIDIA Superchip方案(Vera CPU + GPU),享受NVLink-C2C的超低延迟协同优势;
外围支援区(纯CPU农场):大规模采购AMD EPYC与Intel Xeon,承担RL模拟、合成数据生成、传统软件排程等任务。
这意味着,当前的CPU市场并非“零和博弈”,而是整体规模(TAM)持续扩张的增量市场。
Agentic AI创造了两种截然不同的CPU需求:一种是“与GPU紧密耦合的低延迟控制核心”(NVIDIA主导),另一种是“外围支撑的高核心数并行算力”(AMD/Intel主导)。这正是NVIDIA推出自研CPU后,AMD EPYC依然能在2026年卖到缺货并涨价的核心逻辑。
至此,已经勾勒出清晰的CPU市场版图:NVIDIA的Vera凭借NVLink-C2C技术,锁定GPU机架内部的“控制核心”;AMD的EPYC依靠Chiplet架构的高核心数优势,统治外围的纯CPU市场;Intel的Xeon则凭借x86生态的深厚根基与七成的市场装机量,在传统企业级市场与混合部署场景中,扮演着不可替代的角色。
信息来源:半导体产业纵横






